What is Meta AI? (And Should You Be Worried About Your Data?)
Fri, 26 June 2026

Follow the stories of academics and their research expeditions
I remember when Facebook was just a massive PHP monolith that every developer loved to complain about. We used to joke about how much duct tape was holding the news feed together. Fast forward to today, and they are dropping multi-billion parameter language models on GitHub, shipping custom silicon to their data centers, and completely upending how we build software.
I've spent the last five years in the trenches building machine learning pipelines, fighting with PyTorch environments (which, ironically, Meta built), and watching API pricing models change overnight. I know what corporate tech fluff looks like. We aren't doing fluff today.
If you want to know what this technology actually is, how it works under the hood, and why it matters to your career or business, grab a coffee. We need to talk about open-source weights, GPU hoarding, inference economics, and the messy realities of shipping an AI app.
For anyone who just needs the absolute baseline definition for a slide deck right now: Meta AI is the artificial intelligence research and product division of Meta Platforms Inc. It builds everything from the open-source Llama large language models to the consumer AI chatbots integrated directly into WhatsApp, Facebook, and Instagram.
But that definition doesn't even scratch the surface of the tectonic shift happening here. By Q1 of 2026, Meta AI crossed 1.2 billion monthly active users. That is a 464% increase from 2024. One in four people who use any Meta platform is actively engaging with these AI features. That isn't just an AI study; that is unprecedented consumer scale.
Now, let's look at the actual engineering, the silicon, and the ruthless strategy driving this machine.
Most sites out there blur the lines between the consumer application and the research wing. If you are reading an article about AI on some generic tech blog, they usually treat it all as one big monolithic robot. It's not. If we want to understand the AI company strategy—and why they are actually beating Google in mindshare—we have to split the organization in two.
First, you have FAIR. This is the brain trust. Run by Yann LeCun—one of the literal godfathers of deep learning and a Turing Award winner—FAIR isn't concerned with building a cute chatbot Meta can sell ads against. They are focused on core artificial intelligence research. They publish the heavy mathematical lifting. When you read a groundbreaking artificial intelligence research paper, it's often coming out of FAIR.
Here is the wild thing about FAIR: LeCun actively bets against the generative AI hype train. While OpenAI is obsessed with predicting the next token or generating pixels, FAIR is pushing architectures like JEPA (Joint Embedding Predictive Architecture).
LeCun argues that generating pixels is computationally wasteful and doomed to fail because it produces a "blurry average" of the world. Instead, FAIR’s recent models like V-JEPA (Video-JEPA) predict the future in a latent representation space. Think about it like human learning.
A baby doesn't need to mathematically calculate the pixel-perfect trajectory of a falling cup; they just abstractly understand gravity. V-JEPA does exactly this. It learns the semantic structure of the world from unlabeled video, achieving insane zero-shot robot control metrics without ever reconstructing a single pixel.
Their goal is pushing the boundaries of artificial intelligence machine learning toward actual "World Models."
Then, you have Meta AI—the product division. This is the team taking those theoretical breakthroughs and turning them into scalable AI software. They are the ones building the AI personal assistant you see in your Instagram DMs and packaging the Llama weights for developers.
It’s the difference between inventing a new theory of thermodynamics and manufacturing an engine. When you hear executives from Meta Platforms Inc. talk about their artificial intelligence meta-strategy, they are usually talking about this productization.
They want to integrate an artificial intelligence virtual assistant into the daily habits of billions of users. And with over a billion active endpoints, they’ve already done it.
If you want to understand the modern AI development ecosystem, you have to understand Llama. Llama (Large Language Model Meta AI) is the foundational architecture powering almost everything Meta does right now.
When OpenAI released ChatGPT, they kept the underlying model locked down. It was a black box. You pay for the API token, you send your prompt, and you get a response. You don't own the AI data. You don't own the weights.
Meta did the exact opposite. They took Llama 3 (and eventually the 405 billion parameter behemoths), trained them on over 15 trillion tokens, and essentially open-sourced them. I say "essentially" because there are some commercial use restrictions for companies with hundreds of millions of users, but for 99% of developers doing AI software development, it's totally free.
You can go to GitHub or Hugging Face, download a 70-billion parameter model, and run it locally.
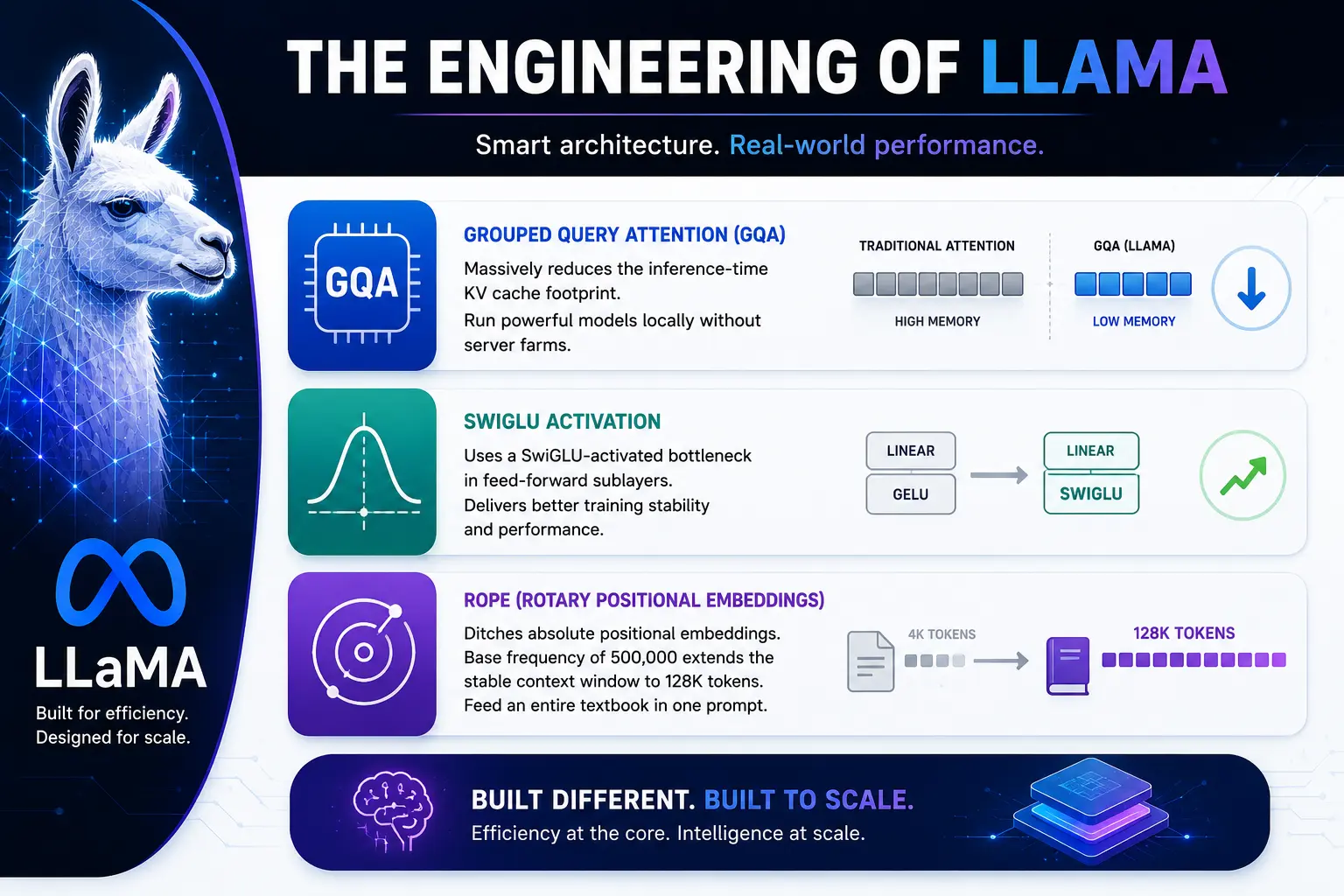
Let’s get technical for a second, because the architecture is brilliant. Llama is an autoregressive decoder-only dense transformer, but they made critical deviations from the standard GPT blueprint.
In older natural language AI models, the Key-Value (KV) cache during inference eats your memory alive. Llama implements GQA to massively reduce the inference-time KV cache footprint. This is why you can actually run these models locally without needing a server farm.
Instead of the standard GeLU activation function used by older models, Llama feed-forward sublayers use a SwiGLU-activated bottleneck. It provides significantly better training stability and empirical performance.
They ditched absolute positional embeddings for RoPE. By bumping the base frequency to 500,000, they pushed the stable context window to an enormous 128K tokens. You can feed an entire textbook into Llama in one prompt.
Why did they do this? Are they just incredibly generous? No. It’s a ruthless, brilliant strategy to commoditize the model layer.
Compute is expensive. Training a massive neural network requires tens of thousands of GPUs running for months. Mark Zuckerberg famously bought up hundreds of thousands of Nvidia H100s, spending billions on server racks and cooling to train these machine learning models.
By giving away the resulting AI technology for free, Meta destroys the business models of companies trying to charge developers for access to basic natural language processing AI.
If I'm building an AI app for business today, I have to make a choice. Do I pay OpenAI a premium for every single API call? Or do I download Llama, fine-tune it on my own secure servers, and own my entire infrastructure?
For serious engineering teams, open-source AI is the only way to guarantee data privacy and control inference costs. Meta gave developers the ultimate weapon, and in return, an entire generation of engineers is now building the future of the internet on Meta's infrastructure.
We can't talk about Meta without talking about hardware. If you are an engineer, you know that training a model is a one-time massive capital expenditure (CapEx). But serving that model—inference—is an operational expenditure (OpEx) that compounds forever.
By late 2024, the math in the AI industry flipped. Inference became 60% to 80% of all AI compute spend. When you are serving an online assistant to 1.2 billion users daily, relying entirely on Nvidia GPUs will bankrupt you.
This is why Meta deployed MTIA (Meta Training and Inference Accelerator).
They are designing custom AI chips and dropping them into their hyperscale fleet of over 1,000,000 servers. They optimize the entire stack—from the PyTorch libraries down to the Linux kernel and the physical memory contiguity in the data center.
By moving Copilot and algorithmic feed traffic off general-purpose Nvidia H100s and onto custom MTIA silicon, they drastically cut the cost per token.
This gives Meta an unfair advantage. They can offer a free, unlimited artificial intelligence chatbot to the entire planet because their unit economics for inference are fundamentally cheaper than a startup renting cloud GPUs.
You don't need to be a developer to interact with this tech. In fact, if you use any Meta Platform Inc. app, you are already generating massive amounts of inference traffic. Let's break down the actual user experience and the staggering adoption numbers.

This is the absolute crown jewel of their strategy. You open WhatsApp, and sitting right in the search bar is a glowing blue ring. That is the Meta AI chatbot. You can ask it to plan a trip, write an email, or translate text on the fly.
As of 2026, WhatsApp dominates Meta AI usage. Over 750 million active users interact with the AI specifically through WhatsApp. That is 63% of all Meta AI interactions globally. Under the hood, your text is routed through NLP pipelines, tokenized, fed into a highly optimized Llama model, and streamed back to your device.
Because it's baked into an app you already check twenty times a day, the friction to use it is zero. You don't have to download a separate AI app or go to a specific AI website. It's just there. This is how you get a third of the global population to adopt artificial intelligence in under three years.
Text is easy; pixels are hard. Meta AI images are powered by foundational models like Emu. When you tell the ai bot in Messenger to "generate a picture of a cyberpunk coffee shop," Emu kicks in.
Unlike older image generation tools that took minutes to render, Meta’s image generation is optimized for aggressive speed. It has to be. If an artificial intelligence app takes ten seconds to return an image in a group chat, the user loses interest.
The caching, latent diffusion optimizations, and rendering pipelines Meta uses to deliver generative AI at this scale without melting their data centers are a masterclass in distributed systems.
This is where the sci-fi stuff gets real. Meta isn't just trapping their AI in your phone. They integrated multimodal AI directly into the Ray-Ban Meta smart glasses. The camera acts as the machine vision input, and the microphone acts as the audio input. You can look at a menu in French and ask the glasses to translate it.
They are pairing this with their "Orion" AR glasses prototypes. This proves that Meta's end goal isn't an AI site; it's ambient intelligence. They want the AI to exist in your physical environment, processing the world exactly as you see it.
Long before we were obsessing over large language models, Meta was using AI deep learning to control what you see. The meta homepage and your Instagram reels feed are entirely dictated by deep learning recommendation models (DLRM).
These are specialized systems that ingest your behavioral data—how long you hovered over a video, what meta posts you shared, and who you muted—and use an artificial intelligence machine learning framework to predict exactly what will keep you scrolling.
It is the most profitable application of AI in human history. When marketing agencies talk about AI in marketing, they are mostly just trying to game these specific recommendation algorithms. In FY2025 alone, Meta’s AI tools drove total revenue to over $200 billion.
The industry is a street fight right now. Every major AI company is scrambling for dominance. Let's do a gritty, honest comparison of where Meta stands against the rest of the pack.
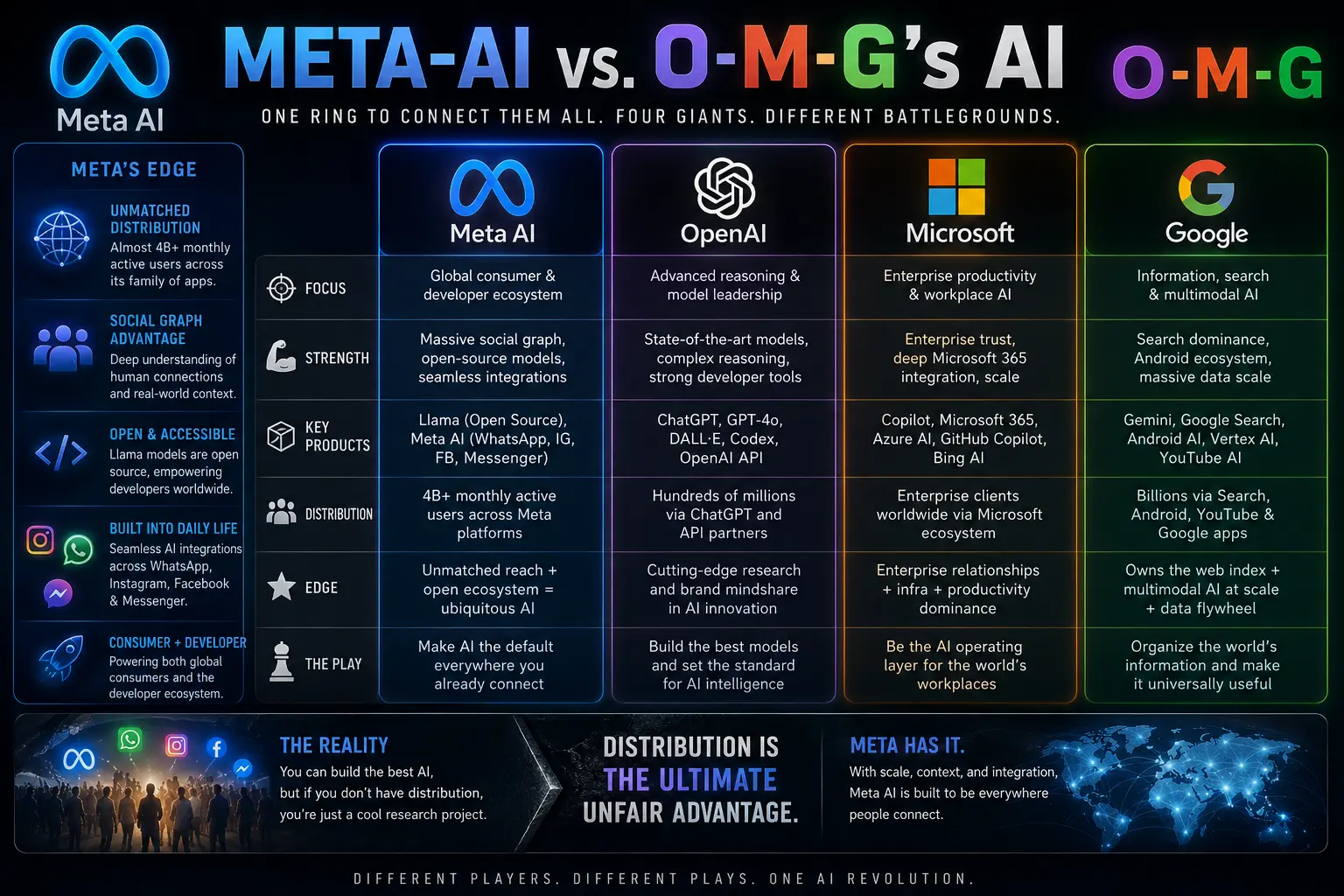
OpenAI is the incumbent. The OpenAI chatbot (ChatGPT) still has the mindshare for complex reasoning and advanced coding tasks. But OpenAI is a walled garden. You have to play by their rules. Meta AI Facebook integrations bring the fight to the consumer's pocket, while Llama brings it to the developer's server. Meta isn't trying to build a better standalone destination URL; they are trying to make the underlying tech ubiquitous.
Google Assistant was the king of the virtual assistant space for years, but it was largely rules-based. Now they are pushing Gemini. Google has a massive advantage in AI search because they own the web index and Android. But Meta has the social graph. When you want an AI personal assistant to summarize a news article, you might use Google. But when you want an AI character to roleplay with in a private chat or need seamless AI translation within a WhatsApp group, Meta wins the context game.
Microsoft poured billions into OpenAI to power their Microsoft AI chatbot (Copilot). They are targeting the enterprise—selling AI tools and a virtual secretary to Fortune 500 companies locked into Office 365. Meta is targeting the developer ecosystem and the global consumer.
Then you have the niche players. You have Perplexity AI trying to reinvent search. You have eleven labs' AI dominating voice generation. But none of them have the raw distribution of metaplatforms. You can build the best natural language AI in the world, but if you don't have distribution, you are just a cool research project. Meta has almost 4 billion monthly active users across its family of apps. That is the ultimate unfair advantage.
Let's drop the corporate shield for a minute. You are talking to a chatbot built by Meta. This is a company whose entire historical business model relies on serving targeted ads. Naturally, people are terrified about AI data and privacy.
What happens when you interact with the meta-artificial intelligence? Are your private group chats being scraped to train the next generation of large language model AI?
Here is the technical reality. Meta explicitly states that your personal end-to-end encrypted (E2EE) messages on WhatsApp are not read or used to train their AI models. The cryptography simply doesn't allow it. They literally cannot read the ciphertext.
However, the interactions you have directly with the Meta chatbot AI are logged. If you prompt the AI-generated function to write a poem or ask it for coding help, that prompt and the resulting AI content are processed on Meta's servers.
This is standard across the industry. Whether you use an OpenAI chat interface, a Microsoft AI tool, or Meta's new AI features, your direct inputs to the bot are generally fair game for telemetry, reinforcement learning from human feedback (RLHF), and system improvement.
If you are deeply concerned about artificial intelligence privacy, the only true solution is to download an open-source model like Llama, isolate it on your local machine, and sever the internet connection. Everything else requires a baseline level of trust in the platform.
To wrap this up, let's hit the rapid-fire questions I get from junior devs and product managers every week.
Yes. For consumers, the AI assistant is embedded freely inside WhatsApp, Instagram, and Facebook. For developers, the Llama artificial intelligence software is open-source and free to download for research and commercial use (with a few exceptions for massive enterprise platforms).
No. They are built by completely different companies using different underlying architectures. ChatGPT is a proprietary language AI owned by OpenAI. Meta’s assistant is powered by their own custom-built Llama large language models.
Yes. By typing a prompt in a supported chat, the system uses Meta's generative AI engine (Emu) to create high-quality images directly within the conversation thread.
While the tools are heavily integrated into their social apps, Meta also maintains a standalone interface. You can search for the official AI platform at meta.ai to interact with the assistant directly in your browser.
The core AI learning frameworks are built heavily on Python, specifically utilizing PyTorch—an open-source machine learning library actually developed by Meta's AI research lab. Low-level optimizations and custom silicon routines often rely on C++ and CUDA.
It simply stands for Meta Artificial Intelligence. It represents both the internal research division (FAIR) and the consumer-facing product teams building out virtual assistants and large language models.
We are living through a massive architectural shift. The era of simple CRUD apps is ending. As an engineer, watching the convergence of AI deep learning, open-source community momentum, custom MTIA silicon, and raw compute power is staggering.
Meta isn't just releasing another AI application; they are aggressively attempting to own the foundational infrastructure of the next decade. Whether you love them or hate them, you can't ignore the code they are shipping.
Fri, 26 June 2026

© 2026 Sprintzeal Americas Inc. - All Rights Reserved.

